










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


DTD语法详细教程:DTD语法详解
更新时间:2020年12月29日15时33分 来源:传智教育 浏览次数:
在编写XML文档时,需要掌握XML语法。同理,在编写DTD文档时,也需要遵循一定的语法。DTD的结构一般由元素类型定义、属性定义、实体定义、记号(notation)定义等构成,一个典型的文档类型定义会把将来要创建的XML文档的元素结构、属性类型、实体引用等预先进行定义。接下来,针对DTD结构中所涉及到的语法进行详细讲解。
一、元素定义
元素是XML文档的基本组成部分,在DTD定义中,每一条<!ELEMENT…>语句用于定义一个元素,其基本的语法格式如下所示:
<!ELEMENT 元素名称 元素内容>
在上面元素的定义格式中,包含了“元素名称”和“元素内容”。其中,“元素名称”是自定义的名称,它用于定义被约束XML文档中的元素,“元素内容”是对元素包含内容的声明,包括数据类型和符号二部分,它共有五种内容形式,具体如下:
(1)#PCDATA:表示元素中嵌套的内容是普通文本字符串,其中,关键字PCDATA是Parsed Character Data的简写。例如<!ELEMENT 书名 (#PCDATA)>表示书名所嵌套的内容是字符串类型。
(2)子元素:说明元素包含的元素。通常用一对圆括号()将元素中要嵌套的一组子元素括起来,例如,<!ELEMENT 书 (书名,作者,售价)>表示元素书中要嵌套书名、作者、售价等子元素。
(3)混合内容:表示元素既可以包含字符数据,也可以包含子元素。混合内容必须被定义零个或多个,例如,<!ELEMENT 书 (#PCDATA|书名)*>表示书中嵌套的子元素书名包含零个或多个,并且书名是字符串文本格式。
(4)EMPTY:表示该元素既不包含字符数据,也不包含子元素,是一个空元素。如果在文档中元素本身已经表明了明确的含义,就可以在DTD中用关键字EMPTY表明空元素。例如,<!ELEMENT br EMPTY>,
其中br是一个没有内容的空元素。
(5)ANY:表示该元素可以包含任何的字符数据和子元素。例如,<!ELEMENT 联系人 ANY>表示联系人可以包含任何形式的内容。但在实际开发中,应该尽量避免使用ANY,因为除了根元素外,其它使用ANY的元素都将失去DTD对XML文档的约束效果。
需要注意的是,在定义元素时,元素内容中可以包含一些符号,不同的符号具有不同的作用,接下来,针对一些常见的符号进行讲解,具体如下:
● 问号[?]:表示该对象可以出现0次或1次。
●星号[*]:表示该对象可以出现0次或多次。
●加号[+]:表示该对象可以出现1次或多次。
● 竖线[|]:表示列出的对象中选择1个。
●逗号[,]:表示对象必须按照指定的顺序出现。
● 括号[()]:用于给元素进行分组。
二、属性定义
在DTD文档中,定义元素的同时,还可以为元素定义属性。DTD属性定义的基本语法格式如下所示:
<!ATTLIST 元素名
属性名1 属性类型 设置说明
属性名1 属性类型 设置说明
......
>
在上面属性定义的语法格式中,“元素名”是属性所属元素的名字,“属性名”是属性的名称,“属性类型”则是用来指定该属性是属于哪种类型,“设置说明”用来说明该属性是否必须出现。关于“属性类型”和“设置说明”的相关讲解,具体如下:
1、设置说明
定义元素的属性时,有四种设置说明可以选择,具体如下:
1)#REQUIRED
表示元素的该属性是必须的,例如,当定义联系人信息的DTD时,我们希望每一个联系人都有一个联系电话属性,这时,可以在属性声明时,使用REQUIRED。
2)#IMPLIED
表示元素可以包含该属性,也可以不包含该属性。比如,当定义一本书的信息时,发现书的页数属性对读者无关紧要,这时,在属性声明时,可以使用IMPLIED。
3)#FIXED
表示一个固定的属性默认值,在XML文档中不能将该属性设置为其它值。使用#FIXED关键字时,还需要为该属性提供一个默认值。当XML文档中没有定义该属性时,其值将被自动设置为DTD中定义的默认值。
4)默认值
和FIXED一样,如果元素不包含该属性,该属性将被自动设置为DTD中定义的默认值。不同的是,该属性的值是可以改变的,如果XML文件中设置了该属性,新的属性值会覆盖DTD中定义的默认值。
2、属性类型
在DTD中定义元素的属性时,有十种属性类型可以选择,具体如下:
1) CDATA
这是最常用的一种属性类型,表明属性类型是字符数据,与元素内容说明中的#PCDATA相同。当然,在属性设置值中出现的特殊字符,也需要使用其转义字符序列来表示,例如,用&表示字符(&),用<表示字符(<)等。
2) Enumerated(枚举类型)
在声明属性时,可以限制属性的取值只能从一个列表中选择,这类属性属于Enumerated(枚举类型)。需要注意的是,在DTD定义中并不会出现关键字Enumerated。接下来通过一个案例来学习如何定义Enumerated类型的属性,如例1所示。
例1 enum.xml
<?xml version="1.0" encoding="GB2312" standalone="yes">
<!DOCTYPE 购物篮 [
<!ELEMENT 购物篮 ANY>
<!ELEMENT 肉 EMPTY>
<!ATTLIST 肉 品种(鸡肉|牛肉|猪肉|鱼肉) "鸡肉">
]>
<购物篮>
<肉 品种="鱼肉"/>
<肉 品种="牛肉"/>
<肉/>
</购物篮>
在例1中,“品种”属性的类型是Enumerated,其值只能为 “鸡肉”、“牛肉”“猪肉”和“鱼肉”,而不能使用其它值。“品种”属性的默认值是“鸡肉”,所以,即使<购物篮>元素中的第三个子元素没有显示定义“品种”这个属性,但它实际也具有“品种”这个属性,且属性的取值为“鸡肉”。
3)ID
一个ID类型的属性用于唯一标识XML文档中的一个元素。其属性值必须遵守XML名称定义的规则。一个元素只能有一个ID类型的属性,而且ID类型的属性必须设置为#IMPLIED或#REQUIRED。因为ID类型属性的每一个取值都是用来标识一个特定的元素,所以,为ID类型的属性提供默认值,特别是固定的默认值是毫无意义的。接下来通过一个案例来学习如何定义一个ID类型的属性,如例2所示。
例2 id.xml
<?xml version="1.0" encoding="GB2312" standalone="yes" ?>
<!DOCTYPE 联系人列表[
<!ELEMENT 联系人列表 ANY>
<!ELEMENT 联系人 (姓名,EMAIL)>
<!ELEMENT 姓名 (#PCDATA)>
<!ELEMENT EMAIL (#PCDATA)>
<!ATTLIST 联系人 编号 ID #REQUIRED>
]>
<联系人列表>
<联系人 编号="1">
<姓名>张三</姓名>
<EMAIL>zhang@itcast.cn</EMAIL>
</联系人>
<联系人 编号="2">
<姓名>李四</姓名>
<EMAIL>li@itcast.cn</EMAIL>
</联系人>
</联系人列表>
在例2中,将元素为<联系人>的编号属性设置为#REQUIRED,说明每个联系人都有一个编号,同时,属性编号的类型为ID,说明编号是唯一的。如此一来,通过编号就可以找到唯一对应的联系人了。
4)IDREF和IDREFS
例2中,虽然张三和李四两个联系人的ID编号是唯一的,但是这两个ID类型的属性没有发挥作用,这时可以使用IDREF类型,使这两个联系人之间建立一种一对一的关系。接下来通过一个案例来学习IDREF类型的使用,如例3所示。
例3 Idref.xml
<?xml version="1.0" encoding="GB2312" standalone="yes" ?>
<!DOCTYPE 联系人列表[
<!ELEMENT 联系人列表 ANY>
<!ELEMENT 联系人 (姓名,EMAIL)>
<!ELEMENT 姓名 (#PCDATA)>
<!ELEMENT EMAIL (#PCDATA)>
<!ATTLIST 联系人
编号 ID #REQUIRED
上司 IDREF #IMPLIED>
]>
<联系人列表>
<联系人 编号="1">
<姓名>张三</姓名>
<EMAIL>zhang@itcast.org</EMAIL>
</联系人>
<联系人 编号="2" 上司="1">
<姓名>李四</姓名>
<EMAIL>li@itcast.org</EMAIL>
</联系人>
</联系人列表>
在例3中,为元素<联系人列表>的子元素<联系人>增加了一个名称为上司的属性,并且将该属性的类型设置为IDREF,IDREF类型属性的值必须为一个已经存在的ID类型的属性值。在第二个<联系人>元素中,将上司属性设置为第一个联系人的编号属性值,如此一来,就形成了两个联系人元素之间的对应关系,即李四的上司为张三。
IDREF类型可以使两个元素之间建立一对一的关系,但是,如果两个元素之间的关系是一对多,例如,一个学生去图书馆可以借多本书。这时,需要使用IDREFS类型来指定某个人借阅了哪些书。需要注意的是,IDREFS类型的属性可以引用多个ID类型的属性值,这些ID的属性值需要用空格分隔。接下来通过一个案例来学习IDREFS的使用,如例4所示。
例4 Library.xml
<?xml version=”1.0” encoding=”GB2312”?>
<!DOCTYPE library[
<!ELEMENT libarary (books,records)>
<!ELEMENT books (book+)>
<!ELEMENT book (title)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT records (item+)>
<!ELEMENT item (data,person)>
<!ELEMENT data (#PCDATA)>
<!ELEMENT person EMPTY>
<!ATTLIST book bookid ID #REQUIRED>
<!ATTLIST person name CDATA #REQUIRED>
<!ATTLIST person borrowed IDREFS #REQUIRED>
]>
<library>
<books>
<book>
<book bookid="b0101">
<title>Java就业培训教材</title>
</book>
<book bookid="b0102">
<title>Java Web开发内幕 </title>
</book>
<book bookid="b0103">
<title>Java开发宝典</title>
</book>
</books>
<records>
<item>
<data>2013-03-13</data>
<person name="张三" borrowed="b0101 b0103"/>
</item>
<item>
<data>2013-05-23</data>
<person name="李四" borrowed="b0101 b0102 b0103"/>
</item>
</records>
</library>
例4中,将元素<book>中属性名为bookid的属性设置为ID类型,元素<person>中名为borrowed的属性设置为IDREFS类型。从Library.xml文档中可以看出,张三借阅了《Java就业培训教材》和《Java开发宝典》这两本书,而李四则借阅了《Java就业培训教材》、《Java Web开发内幕》和《Java开发宝典》这三本书。
5)NMTOKEN和NMTOKENS
NMTOKEN是Name Token的简写,它表示由一个或者多个字母、数字、句点(.)、连字号(-)或下划线(_)所组成的一个名称。NMTOKENS关键字表示一种列表类型。一个元素的NMOTOKENS类型的属性设置值可以是同一个XML文件中的另外多个NMTOKEN类型的属性的设置值,每个NMTOKEN属性值之间用空格分隔。具体示例如下:
<!ELEMENT 用户 EMPTY> <!ATTLIST 用户 姓名 NMTOKEN #REQUIRED> <!ELEMENT 数据 (#PCDATA)> <!ATTLIST 数据 授权用户 NMTOKENS #IMPLIED>
在上面的示例中,元素<用户>的“姓名”属性指定为NMTOKEN类型,元素<数据>的“授权用户”属性指定为NMTOKENS,与这段DTD定义语句对应的XML具体如下:
<用户 姓名="张三">
<用户 姓名="李四">
<数据 授权用户="张三 李四">
这里是一些授权访问的数据
</数据>
6)NOTATION
现实世界中存在很多无法或不易用XML格式组织的数据,例如图像、声音、影像等等。对于这些数据,XML应用程序常常并不提供直接的应用支持,但可以通过设置NOTATION类型的属性来让一个外部应用程序进行处理。在DTD文件中,NOTATION定义语句分为两种情况,具体如下:
第一种情况:<!NOTATION 符号名 SYSTEM "MIME类型"> 第二种情况:<!NOTATION 符号名 SYSTEM "URL路径名">
在上述定义语句中,第一种情况指定数据的MIME类型,第二种情况指定处理程序的URL路径。当使用NOTATION类型作为属性的类型时,首先要在DTD中使用<!NOTATION…>语句定义相应的notation,接下来通过一个例来演示NOTATION属性的使用,如例5所示。
例5 notation.xml
<?xml version="1.0" encoding="GB2312" standalone="yes"?>
<!DOCTYPE 文件[
<!NOTATION mp SYSTEM "movPlayer.exe">
<!NOTATION gif SYSTEM "Image/gif">
<!ELEMENT 文件ANY>
<!ELEMENT 电影 EMPTY>
<ELEMENT 电影 演示设备 NOTATION (mp|gif) #REQUIRED>
<文件>
<电影 演示设备=”mp”/>
<文件>
在例5中,元素<电影>指定了两种可选的演示设备,一种是movPlayer.exe,一种是用来绘制GIF图像的应用程序。
7)ENTITY和ENTITYS
ENTITY对应的中文意思为实体(关于实体定义的细节,将在后面进行介绍)。当某个属性的类型设置为ENTITY时,表明其属性值必须为在DTD中使用<!ENTITY …>语句定义的一个实体(entity)的引用。接下来看一段DTD定义的语句,具体如下:
<!ENTITY itcast "传智播客论坛交流,www.itcast.cn"> <!ELEMENT 电影 EMPTY> <!ATTLIST 电影 来源 ENTITY #REQUIRED>
与这段DTD定义语句对应的XML数据片断如下:
<电影 来源="&itcast;" />
需要注意的是,只有引用实体才可以作为ENTITY类型属性的设置值,参数实体不能用作ENTITY类型的属性的设置值。关于参数实体和引用实体的相关讲解,将在实体定义中进行详细讲解。
ENTITYS关键字用于表示一种列表类型,一个元素的ENTITYS类型的属性设置值可以是多个实体的引用,每个实体的引用之间用空格分隔,具体示例如下:
<!ENTITY banner SYSTEM "http://www.itcast.cn/images/topword.gif"> <!ENTITY logo SYSTEM "http://www.itcast.cn/images/logo.gif"> <!ATTLIST image src ENTITIES #REQUIRED>
根据上面的DTD语句,如果想通过src属性引用两幅图像,则对应的XML数据如下所示:
<img src="logo banner">
三、实体定义
有时候需要在多个文档中调用同样的内容,比如公司名称,版权声明等,为了避免重复输入这些内容,可以通过<!ENTITY…>语句定义一个表示这些内容的实体,然后在各个文档中引用实体名替代它所表示的内容。实体可分为两种类型,分别是引用实体和参数实体,接下来,针对这两种实体类型进行详细地讲解。
1)引用实体
引用实体的语法定义格式有两种:
(1)<!ENTITY 实体名称 "实体内容"> (2)<!ENTITY 实体名称 SYSTEM "外部XML文档的URL">
引用实体用于解决XML文档中内容重复的问题,其引用方式方法为:
&实体名称;
了解了引用实体的语法格式及其在XML文档中的引用方式,接下来通过一个案例来学习,如例6和例7所示。
例6 book.dtd
<!ENTITY itcast "传智播客官网,www.itcast.cn"> <!ELEMENT 书架 (书+)> <!ELEMENT 书 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)> <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售价 (#PCDATA)>
例7 book.xml
<?xml version="1.0" encoding="GB2312"?>
<!DOCTYPE 书架 SYSTEM "book.dtd">
<书架>
<书>
<书名>Java就业培训教程</书名>
<作者>&itcast;</作者>
<售价>39.9</售价>
</书>
<书>
<书名>EJB3.0入门经典</书名>
<作者>黎活明</作者>
<售价>39.00元</售价>
</书>
</书架>
用IE9.0以下的浏览器打开book.xml文件,浏览器显示的结果如图1所示。
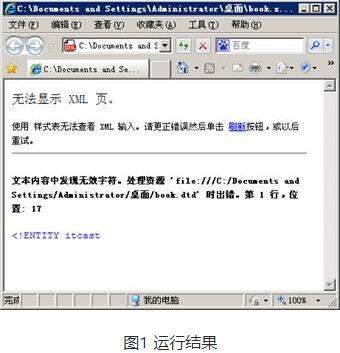
图1提示的错误信息是“文本内容中发现无效字符。”这是因为book.dtd文件使用的是本地字符集编码,即GB2312编码,而DTD文件应该使用UTF-8或者Unicode编码。需要注意的是,IE9以上版本的浏览器也不会提示错误。
接下来我们将book.dtd按照UTF-8编码方式进行重新保存,保存方式如图2所示。
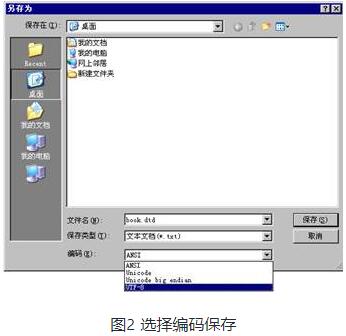
按照图2的方式完成编码保存后,用IE浏览器重新打开book.xml文件或者单击图1-10工具栏中的“刷新”按钮,浏览器显示的结果如图3所示。
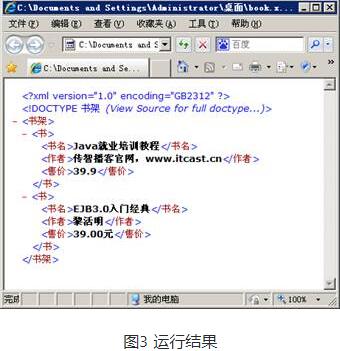
从图1、3中可以看出,book.xml文件中的“&itcast;”被显示成“传智播客官网,www.itcast.cn”。
2)参数实体
参数实体只能被DTD文件自身使用,它的语法格式为:
<!ENTITY % 实体名称 "实体内容">
需要注意的是,在声明参数实体时,ENTITY、%、实体名和“实体内容”之间各有一个空格。
引用参数实体的方式是:
%实体名称;
了解了参数实体的语法格式和引用方式,接下来通过一段示例代码来演示参数实体的定义,具体如下:
<!ENTITY % TAG_NAME "姓名|EMAIL|电话|地址"> <!ELEMENT 个人信息 (%TAG_NAME; |生日)> <!ELEMENT 客户信息 (%TAG_NAME; |公司名)>
在上面的示例中,DTD中定义了两个元素,分别是“个人信息”和“客户信息”,这两个元素的定义中都包含了“姓名| EMAIL|电话|地址”这一相同的部分,因此,可以将相同的部分定义为一个TAG_NAMES的参数实体,然后将“个人信息”和“客户信息”这两个元素的定义规则中的“姓名 | EMAIL | 电话 | 地址”部分替换成对TAG_NAMES这个参数实体的引用即可。
参数实体不仅可以简化元素中定义的相同内容,还可以简化属性的定义,具体示例如下:
<!ENTITY % common.attributes
'id ID #IMPLIED
account CDATA #REQUIRED'
>
<!ELEMENT purchaseOrder (item+, manufacturer)>
<!ELEMENT item (price, quantity)>
<!ELEMENT manufacturer (#PCDATA)>
<!ATTLIST purchaseOrder %common.attributes;>
<!ATTLIST item %common.attributes;>
<!ATTLIST manufacturer %common.attributes;>
在上面的示例中,由于多个元素都具有id和account这两个属性的相同定义,因此,可以将这两个属性的文本内容定义为一个名称为common.attributes的参数实体。当定义元素的属性时,通过引用common.attributes 这个参数实体,将该参数实体转换为id和account 这两个属性所定义的文本内容了。
值得一提的是,当DTD的元素和属性定义中要出现大量相同内容时,参数实体是一种非常不错的选择。因为如果需要修改DTD中相同的部分,只需要在参数实体的定义中修改即可。
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
