










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


IDEA工具开发WordCount单词计数程序的相关步骤有哪些?
更新时间:2020年12月17日16时04分 来源:传智教育 浏览次数:

Spark作业与MapReduce作业同样可以先在本地开发测试,本地执行模式与集群提交模式,代码的业务功能相同,因此本书大多数采用本地开发模式。下面讲解使用IDEA工具开发WordCount单词计数程序的相关步骤。
1.创建Maven项目,新建资源文件夹
创建一个Maven工程项目,名为“spark_chapter02”。项目创建好后,在main和test目录下分别创建一个名称为scala的文件夹,创建好的目录结构如图1所示。
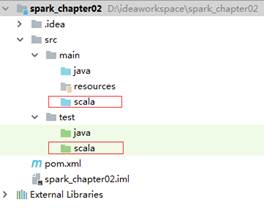
图1 Spark_chapter02项目目录结构
在图1中,选中main目录下的scala文件夹,单击右键选择【Mark Directory as】→【Sources Root】,将文件夹标记为资源文件夹类型;同样的,选中test目录下的scala文件夹,单击右键选择【Mark Directory as】→【Test Sources Root】将文件夹标记为测试资源文件夹类型。其中,资源文件夹中存放项目源码文件,测试文件夹中存放开发中测试的源码文件。
2.添加Spark相关依赖、打包插件
Maven是一个项目管理工具,虽然我们刚才创建好了项目,但是却不能识别Spark类,因此,我们需要将Spark相关的依赖添加到Maven项目中。打开pom.xml文件,在该文件中添加的依赖如下所示:
2.11.8
2.7.4
2.3.2
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_2.11
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
在上述配置参数片段中,标签用来设置所需依赖的版本号,其中在标签中添加了Scala、Hadoop和Spark相关的依赖,设置完毕后,相关Jar文件会被自动加载到项目中。
3.编写代码,查看结果
在main目录下的scala文件夹中,创建WordCount.scala文件用于词频统计,代码如文件1所示。
文件1 WordCount.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//编写单词计数
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象,设置appName和Master地址
val sparkconf = new
SparkConf().setAppName("WordCount").setMaster("local[2]")
//2.创建SparkContext对象,它是所有任务计算的源头,
// 它会创建DAGScheduler和TaskScheduler
val sparkContext = new SparkContext(sparkconf)
//3.读取数据文件,RDD可以简单的理解为是一个集合
// 集合中存放的元素是String类型
val data : RDD[String] =
sparkContext.textFile("D:\\word\\words.txt")
//4.切分每一行,获取所有的单词
val words :RDD[String] = data.flatMap(_.split(" "))
//5.每个单词记为1,转换为(单词,1)
val wordAndOne :RDD[(String, Int)] = words.map(x =>(x,1))
//6.相同单词汇总,前一个下划线表示累加数据,后一个下划线表示新数据
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//7.收集打印结果数据
val finalResult: Array[(String, Int)] = result.collect()
println(finalResult.toBuffer)
//8.关闭sparkContext对象
sparkContext.stop()
}
}
上述代码中,第7-11行代码创建SparkContext对象并通过SparkConf对象设置配置参数,其中Master为本地模式,即可以在本地直接运行;第14-24行代码中,读取数据文件,将获得的数据按照空格切分,将每个单词记作(单词,1),之后若出现相同的单词就将次数累加,最终打印数据结果;第26行代码表示关闭SparkContext对象资源。执行代码成功后,在控制台可以查看输出结果,如图2所示。
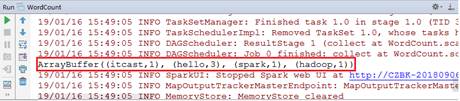
图2 IDEA开发WordCount
从图2可以看出,文本中的单词已经成功统计了出现的次数。
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
